MPS-DF is the data-flow support in the MPS language workbench. It supports the definition
and efficient execution of data-flow analyses. Users of MPS-DF first define data-flow builders for the analyzed
language. These builders contribute subgraphs to the data-flow graph (DFG), an intermediate program representation
encoding the data-flow of the analyzed program. MPS-DF then supports defining data-flow analyses, on the DFG, which
compute some data-flow specific knowledge (e.g. which variables are initialized) about the program. These data-flow
analyses are static program analyses, which derive the knowl- edge without actually running the analyzed program. Finally,
existing MPS components, such as program validators, transformations or refactorings, make use of this knowledge.
MPS-DF has two important characteristics: extensibility and variable precision.
Extensibility is motivated by the fact that MPS-based languages are extensible themselves (wrt. syntax, semantics, IDE support).
It comes in two flavours: first, builders enable extensibility of the DFG in the face of language extensions of the analyzed language.
This means that an existing analysis immediately works on an extended program if the concepts in the language extension also define
builders and thus contribute subgraphs to the DFG. The second flavour of extensibility supports augmenting the DFG for a particular
analysis with custom nodes that encode specific knowledge about the analyzed program and potentially override an analysis result based on that knowledge.
Variable precision considers performance trade-offs: real-time checks in the IDE must run fast, possibly compromising on precision,
whereas a more precise, but slower, analysis is needed during compilation. We achieve the variable precision by switching between
intra-procedural analysis (within a sin- gle function definition) and inter-procedural analysis (across function definitions).
Switching is achieved by constructing two different DFGs, but running the same analyses.
mbeddr for the inter-procedural analyses and the case studies
1 - Highlights
MPS-DF provides a DSL for the definition of data-flow graph builders. Builders contribute subgraphs to the data-flow graph,
which is an intermediate program representation encoding the control flow of the program together with the data-flow.
MPS-DF provides a DSL for the definition of data-flow analyses which derive some data-flow specific knowledge on the DFG of the analyzed program.
MPS-DF provides extensive support for extensibility which aligns perfectly with the support for language extensions in MPS.
Data-flow analyses can be evaluated with varying precision levels; clients can switch between a more precise and potentially slower inter-procedural
analysis and a less precise but faster intra-procedural analysis.
Results of MPS-DF analyses can immediately be used in already existing MPS components: validation rules, generators, refactorings.
The following video also highlights the various aspects of the project:
2 - Getting Started
At the time of the ASE submission only the intra-procedural part of MPS-DF is integrated into MPS. The inter-procedural part is
part of the mbeddr project and it is being integrated into core MPS during the summer. The plan is that the upcoming major release of
MPS (version 3.4) will already contain all MPS-DF components.
You can download the corresponding MPS version from here
and you may find the MPS user guide interesting as well.
You can obtain the inter-procedural part along with the case studies from the mbeddr repository. Simply check out the feature/mps-df branch which
also contains the example projects used in the paper and in the above video for demonstration. The relevant MPS modules for the inter-procedural
data-flow analyses are the com.mbeddr.mpsutil.dataflow language and the com.mbeddr.mpsutil.dataflow.runtime solution from the mpsutil project in mbeddr.
3 - Case studies
We have developed several data-flow analyses for C in mbeddr and for Java in MPS itself. The analyses implementations are readily available
once you obtained the above mentioned software components.
In order to find these analysis implementations you simply need to press CTRL (or CMD on Mac) + N in MPS and type in the analysis name.
MPS will automatically jump to the declaration of the analyses. The name of the analyses are given below in parentheses. In the following we give details about four analyses.
Points-to Analysis for C (PointsTo)
Synopsis: derives the possible targets of a pointer typed variable at a program point (DFG node).
Lattice element: Map<node<Var>, Set<node<Var>>> which represents a mapping from variables to set of variables.
Analysis direction: forward, because the points-to relationship is something that happened in the past and we carry that over to later nodes in the DFG.
Must/May property: must analysis, because we want this analysis to be a sound analysis, claiming that a variable points to another only if this relationship holds
on all execution paths that lead to a program point.
Initialized Variables Analysis for C (InitializedVariables)
Synopsis: derives which variables are definitely initialized at a program point (DFG node).
Lattice element: Set<node<Var>> which represents the set of initialized variables.
Analysis direction: forward, because the initialized property is something that happened in the past and we carry that over to later nodes in the DFG.
Must/May property: must analysis, because we want this analysis to be a sound analysis, claiming the initialized property about a variable only when it
is guaranteed to have been initialized on all execution paths that lead to a program point.
Custom instructions: The analysis uses only one custom instruction, defInit(node<Var> target), which represents a definitely initialized variable.
The presence of the custom instruction in the DFG overrides the analysis result by considering the target variable initialized.
Other: The analysis uses the results of the points-to analysis to know which pointer typed variables point to which other variables.
This is necessary, because whenever an assignment of the form *a = 10; happens, we do not directly initialize the variable
a, but those variables which a may point to.
Liveness Analysis for C (Liveness)
Synopsis: the analysis derives which variables are live at a program point (DFG node),
where live means that the current value of the variable may be read during the remaining execution of the program.
Lattice element: Set<node<Var>> which represents the set of live variables.
Analysis direction: backward, because the current value of a variable may be read in the future, thus we need to propagate the information from the back to the front.
Must/May property: may analysis, because we consider a variable live if it is read on any of the succeeding execution paths. Here, we deliberately compute
and upper approximation of the data-flow knowledge at runtime.
Null Analysis for Java (Nullable)
Synopsis: the analysis derives the nullable state of a variable or an expression.
This information is used to prevent null pointer dereferencing in Java code.
Lattice element: Map<node<>, NullableState> which represents the nullable state of an expression or a variable.
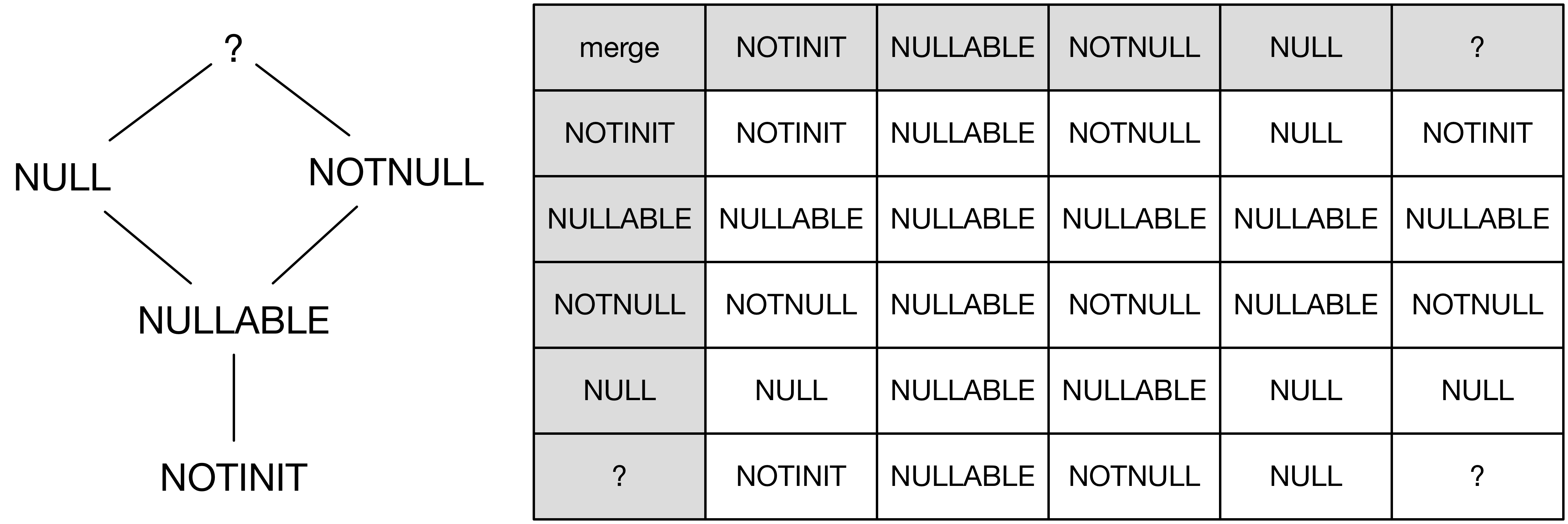
The NullableState itself is also a lattice which consists of the following elements:
NOTINIT: assigned to an uninitialized variable. This is used to filter out null pointer dereferencing errors which
originate from reads from uninitialized variables. These kinds of errors are caught by an uninitialized read analysis for Java.
NULLABLE: expression/variable may be null,
NOTNULL: expression/variable is definitely not null.
NULL: expression/variable is definitely null.
?: this element is never assigned by the analysis, but we use this element as the least upper bound for NULL and NOTNULL.
The lattice itself is depicted on the left in the following figure. We define a merge function which can be used to combine two lattice elements together.
The implementation of the merge function is given with the table on the right in the following figure. The introduction and handling of NOTINIT may
seem strange at first, but we emphasise that uninitialized read errors are caught by another analysis. Forgetting about NOTINITs is also accelerated by merge, because it
picks the other element whenever we combine a NOTINIT with something else.
Analysis direction:forward, because the analysis result depends on previous assignments (or the absence of them) which happened in the past.
Must/May property:must analysis, because we want this analysis to be a sound analysis, claiming that an expression/variable is definitely null/not null only if this fact holds on
all execution paths that lead to a program point.
Custom instructions:The analysis uses three custom instructions: nullable, notNull and null.
All of these custom instructions have one parameter of type node<> which represents an expression or a variable.
nullable is inserted into the DFG when a variable (or parameter) is annotated with the @Nullable annotation.
notNull is inserted if a variable (or parameter) is annotated with the @NotNull annotation or
the variable/expression is assigned a definitely not null expression.
null is inserted for the variables and expressions when the null literal is assigned to them.